Neural Networks
Introduction
Neural networks exist in a variety of different architectures and have been implemented in numerous financial applications. However, the most widely used architecture for the analysis of stock markets is known as the MLP neural network.
A generic neural network is built with at least three layers comprising an input, hidden and output layer. The input layer structure is determined by the number of explanatory variables depicted as nodes in the architecture. The hidden layer represents the capacity of complexity in which the model can support or ‘fit’. Moreover, both the input and hidden layers contain what is known as a bias node. The value attributed to this node is a fixed value and is equal to one. Its purpose is similar to the functionality of which the intercept serves in more traditional regression models. The final and third layer of a standard neural network, the output layer, is governed by a structure of nodes corresponding to a number of response variables. Furthermore, each of these layers is linked via a node-to-node interconnecting system enabling a functional network of ‘neurons’.
On the whole, neural networks learn and identify relationships in data using neurons similar to how the human brain works. They are a non-parametric tool and use a series of waves and neurons to capture even very complex relationships between the predictor inputs and the target variables. They can overcome messy data such as noise and imprecision in the measurement system. Neural networks are appropriate for regression as well as classification, time series analysis and clustering.
Multi Layer Perceptron
The MLP allows the user to select a set of activation functions to explore including identity, logistic, hyperbolic tangent, negative exponential and sine. These activation functions can be used for both hidden and output neurons. MLP also trains networks using a variety of algorithms such as gradient descent and conjugant descent.
Implementation
Example
# Import package necessary for splitting the dataset.
from sklearn.model_selection import train_test_split
# Import package to generate a synthetic dataset.
from sklearn.datasets import make_regression
# Import package to quantify final prediction score.
from sklearn.metrics import r2_score
# Import the mlp implementation from arbitragelab.
from arbitragelab.ml_approach.neural_networks import MultiLayerPerceptron
# Generate 500 samples with 100 features, to be used as our dataset.
X, y = make_regression(500)
# Get number of samples to be given to the network.
_, frame_size = X.shape
# Initialize a basic regression neural network.
regressor = MultiLayerPerceptron(frame_size, num_outputs=1, loss_fn="mean_squared_error",
optmizer="adam", metrics=[],
hidden_layer_activation_function="relu",
output_layer_act_func="linear")
# This will compile the keras model structure implemented.
regressor.build()
# Will supply information about the structure of the model.
regressor.summary()
# Prepare dataset for training and testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)
# Fit compiled model with training data.
regressor.fit(X_train, y_train,
batch_size=20, epochs=400,
verbose=1)
# Plot loss vs epochs.
regressor.plot_loss()
# Finally use the fitted model to predict test set.
predictions = r2_score(y_test, regressor.predict(X_test))
Recurrent Neural Network (LSTM)
Recurrent neural networks (RNNs) are neural networks that leverage backpropagation through time (BPTT) algorithm to determine the gradients. Through this process, RNNs tend to run into two problems, known as exploding gradients and vanishing gradients. These issues are defined by the size of the gradient, which is the slope of the loss function along the error curve. When the gradient is too small, it continues to become smaller, updating the weight parameters until they become insignificant. When that occurs, the algorithm is no longer learning. Exploding gradients occur when the gradient is too large, creating an unstable model.
Long Short Term Memory (LSTM) was first introduced by (Hochreiter and Schmidhuber 1997) as a solution to overcome error back-flow problems in RNN. An LSTM is capable of retaining and propagating information through the dynamics of the LSTM memory cell, hidden state, and gating mechanism.
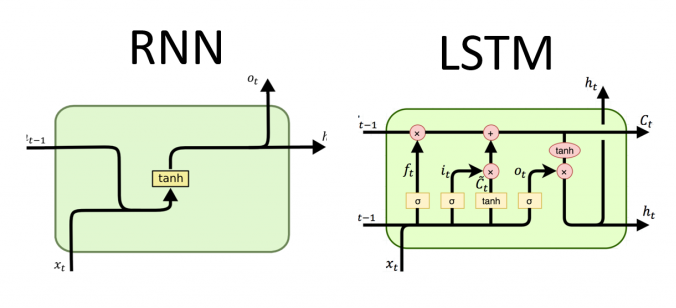
Visual interpretation of the internal structures of RNNs and LSTMs. (Olah 2015).
Implementation
Example
# Import package necessary for splitting the dataset.
from sklearn.model_selection import train_test_split
# Import package to generate a synthetic dataset.
from sklearn.datasets import make_regression
# Import package to quantify final prediction score.
from sklearn.metrics import r2_score
# Import the rnn implementation from arbitragelab.
from arbitragelab.ml_approach.neural_networks import RecurrentNeuralNetwork
# Generate 500 samples with 100 features, to be used as our dataset.
X, y = make_regression(500)
# Prepare dataset for training and testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)
n_features = 1
# Reshape from [samples, timesteps] into [samples, timesteps, features].
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], n_features))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], n_features))
_, frame_size, no_features = X_train.shape
# Initialize a basic regression recurrent neural network.
regressor = RecurrentNeuralNetwork((frame_size, no_features), num_outputs=1,
loss_fn="mean_squared_error", optmizer="adam",
metrics=[], hidden_layer_activation_function="relu",
output_layer_act_func="linear")
# This will compile the keras model structure implemented.
regressor.build()
# Will supply information about the structure of the model.
regressor.summary()
# Fit compiled model with training data.
regressor.fit(X_train, y_train,
batch_size=20, epochs=400,
verbose=1)
# Plot loss vs epochs.
regressor.plot_loss()
# Finally use the fitted model to predict test set.
predictions = r2_score(y_test, regressor.predict(X_test))
Higher Order Neural Network
As explained by (Giles and Maxwell 1987), HONNs exhibit adequate learning and storage capabilities due to the fact that the order of the network can be structured in a manner which resembles the order of the problem.
Although the extent of their use in finance has so far been limited, (Knowles et al. 2009) show that, with shorter computational times and limited input variables, ‘the best HONN models show a profit increase over the MLP of around 8%’.
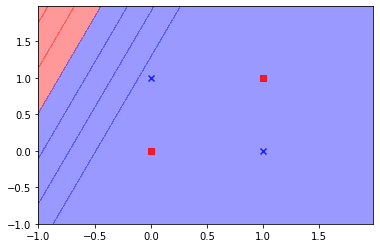
An example showing the capability of HONNs, is the XOR problem. The Exclusive OR problem could not be solved with a network without a hidden layer or by a single layer of first-order units, as it is not linearly separable. However, the same problem is easily solved if the patterns are represented in three dimensions in terms of an enhanced representation (Pao, 1989), by just using a single layer network with second-order terms.
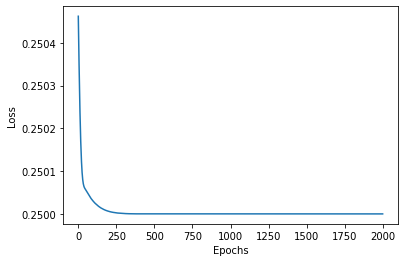
MLP trying to solve the Exclusive OR problem.
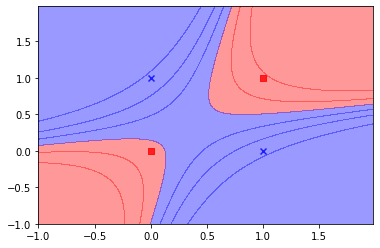
HONN output.
Typically HONNs are split into two types; the first type uses feature engineering to expand the input dataset in representing the higher-order relationships in the original dataset. The second type uses architectural modifications to augment the ability of the network to find higher-order relations in the dataset.
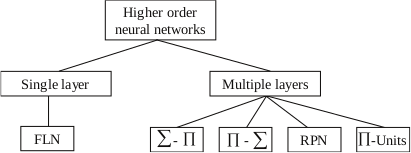
HONNs can be classified into single and multiple layer structures, as explained by (Liatsis et al. 2009).
Single Layer - Functional Link NNs (Dehuri et al. 2010)
Single-layer, higher-order networks consist of a single processing layer and inputs nodes, such as the functional link network (FLN) (Pao, 1989), which functionally expands the input space, by suitable pre-processing of the inputs.
In contrast to a feed-forward ANN structure, i.e., a multilayer perceptron (MLP), the FLANN is basically a single-layer structure in which nonlinearity is introduced by enhancing the input pattern with nonlinear functional expansion. With proper choice of functional expansion in a FLANN, this network performs as good as and in some cases even better than the MLP structure for the problem of nonlinear system identification.
The dimensionality of the input space for FLNs can be increased in two ways (Pao, 1989):
The tensor or output product model, where the cross-products of the input terms are added to the model. For example, for a network with three inputs \(X_1, X_2,\) and \(X_3\), the cross products are: \(X_1 X_2, X_1 X_3, X_2 X_3\) , therefore adding second-order terms to the network. Third-order terms such as \(X_1 X_2 X_3\) can also be added.
Functional expansion of base inputs, where mathematical functions are used to transform the input data.
Due to the nature of single layer HONNs and the fact that the number of inputs can be numerous, orders of 4 and over are rarely used.
Implementation
Example
# Import package necessary for splitting the dataset.
from sklearn.model_selection import train_test_split
# Import package to generate a synthetic dataset.
from sklearn.datasets import make_regression
# Import package to quantify final prediction score.
from sklearn.metrics import r2_score
# Import the feature expander implementation from arbitragelab.
from arbitragelab.ml_approach.feature_expander import FeatureExpander
# Import the mlp implementation from arbitragelab.
from arbitragelab.ml_approach.neural_networks import MultiLayerPerceptron
# Generate 500 samples with 100 features, to be used as our dataset.
X, y = make_regression(500)
expanded_X = FeatureExpander(methods=['product', 'power'], n_orders=2).fit(X).transform()
# Get number of samples to be given to the network.
n_frames, frame_size = expanded_X.shape
# Initialize a basic regression neural network.
regressor = MultiLayerPerceptron(frame_size, num_outputs=1, loss_fn="mean_squared_error",
optmizer="adam", metrics=[],
hidden_layer_activation_function="relu",
output_layer_act_func="linear")
# This will compile the keras model structure implemented.
regressor.build()
# Will supply information about the structure of the model.
regressor.summary()
# Prepare dataset for training and testing.
X_train, X_test, y_train, y_test = train_test_split(expanded_X, y, test_size=0.3, shuffle=False)
# Fit compiled model with training data.
regressor.fit(X_train, y_train,
batch_size=20, epochs=100,
verbose=1)
# Plot loss vs epochs.
regressor.plot_loss()
# Finally use the fitted model to predict test set.
predictions = r2_score(y_test, regressor.predict(X_test))
Multiple Layer NNs (Ghazali et al. 2009)
Multilayered HONNs incorporate hidden layers, in addition to the output layer. A popular example of such structures is the sigma-pi network, which consists of layers of sigma-pi units (Rumelhart, Hinto & Williams, 1986). A sigma-pi unit consists of a summing unit connected to a number of product units, whose order is determined by the number of input connections. Another architecture that belongs to this category is the pi-sigma network (Shin & Ghosh, 1992). This consists of a layer of summing units, connected to a single product unit. The output of the product unit is usually passed through a nonlinear transfer function.
The main difference between the pi-sigma and the sigma-pi networks is that the former utilise a smaller number of weights, however, they are not universal approximators. To address this disadvantage, (Shin & Ghosh 1991) proposed an extension to the pi-sigma network, the so-called ridge polynomial neural network (RPN), which consists of a number of increasing order pi-sigma units. Most of the above networks have one layer of trainable weights, and hence simple weights updating procedures can be used for their training.
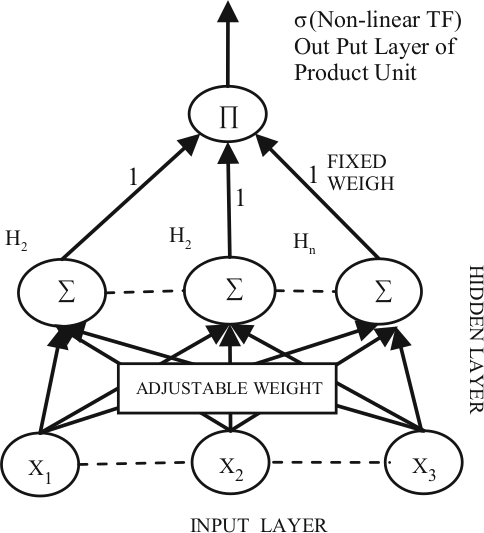
Visual representation of the Pi-Sigma Neural Network architecture. (Ghazali, R. and Al-Jumeily, D., 2009)
Implementation
Example
# Import package necessary for splitting the dataset.
from sklearn.model_selection import train_test_split
# Import package to generate a synthetic dataset.
from sklearn.datasets import make_regression
# Import package to quantify final prediction score.
from sklearn.metrics import r2_score
# Import the psnn implementation from arbitragelab.
from arbitragelab.ml_approach.neural_networks import PiSigmaNeuralNetwork
# Generate 500 samples with 100 features, to be used as our dataset.
X, y = make_regression(500)
# Get number of samples to be given to the network.
n_frames, frame_size = X.shape
# Initialize a basic regression pi sigma neural network.
regressor = PiSigmaNeuralNetwork(frame_size, num_outputs=1, loss_fn="mean_squared_error",
optmizer="adam", metrics=[],
hidden_layer_activation_function="relu",
output_layer_act_func="linear")
# This will compile the keras model structure implemented.
regressor.build()
# Will supply information about the structure of the model.
regressor.summary()
# Prepare dataset for training and testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)
# Fit compiled model with training data.
regressor.fit(X_train, y_train,
batch_size=20, epochs=100,
verbose=1)
# Plot loss vs epochs.
regressor.plot_loss()
# Finally use the fitted model to predict test set.
predictions = r2_score(y_test, regressor.predict(X_test))