Note
The following documentation closely follows the papers:
Sparse Mean-reverting Portfolio Selection
Introduction
Assets that exhibit significant mean-reversion are difficult to find in efficient markets. As a result, investors focus on creating long-short asset baskets to form a mean-reverting portfolio whose aggregate value shows mean-reversion. Classic solutions, including cointegration or canonical correlation analysis, can only construct dense mean-reverting portfolios, i.e. they include every asset in the investing universe. These portfolios have shown significant such as higher transaction costs, worse P&L interpretability, and inability to capture meaningful statistical arbitrage opportunities. On the other hand, sparse mean-reverting portfolios, which require trading as few assets as possible, can mitigate these shortcomings.
This module provides all the tools to construct sparse mean-reverting portfolios, including:
Covariance selection and penalized regression techniques to narrow down the investing universe
Greedy search to construct sparse mean-reverting portfolios
Semidefinite programming (SDP) approach to construct sparse mean-reverting portfolios above a volatility threshold
In addition, the module also includes Box-Tiao canonical decomposition for constructing dense mean-reverting portfolios and Ornstein-Uhlenbeck (OU) model fitting to directly compare mean-reversion strength of the portfolios.
Mean-reversion Strength Metrics and Proxies
Suppose the investing universe consists of \(n\)-assets, and the sparse mean-reverting portfolio selection problem can be summarized as follows:
Note
Maximize the mean-reversion strength, while trading \(k\)-assets (\(k \ll n\)) in the portfolio.
One solution is to assume the portfolio value follows an Ornstein-Uhlenbeck (OU) process and use the mean-reversion speed parameter \(\lambda\) to measure the mean-reversion strength.
However, it is hard to express the OU mean-reversion speed \(\lambda\) as a function of the portfolio weight vector \(\mathbf{x}\). Instead of optimizing \(\lambda\), this module will only use \(\lambda\) to evaluate the sparse portfolios generated and employ three other mean-reversion strength proxies to solve the sparse mean-reverting portfolio selection problem.
Predictability based on Box-Tiao canonical decomposition.
Portmanteau statistic.
Crossing statistic.
Predictability and Box-Tiao Canonical Decomposition
Univariate Case
Assume that the portfolio value \(P\) follows the univariate recursion below:
where \(\hat{P}_{t-1}\) is a predictor of \(x_t\) built upon all past portfolio values recorded up to \(t-1\), and \(\varepsilon_t\) is a vector i.i.d. Gaussian noise, where \(\varepsilon_t \sim N(0, \Sigma)\), independent of all past portfolio values \(P_0, P_1, \ldots, P_{t-1}\).
Now calculate the variance of the both sides of the equation:
Denote the variance of \(x_t\) by \(\sigma^2\), the variance of \(\hat{x}_{t-1}\) by \(\hat{\sigma}^2\), then we can write the above equation as:
The predictability is thus defined by the ratio:
and its meaning is straightforward. When \(\nu\) is small, the variance of the Gaussian noise \(\Sigma\) dominates and the portfolio value process will look like noise and is more strongly mean-reverting. Otherwise, the variance of the predicted value \(\hat{\sigma}^2\) dominates and the portfolio value process can be accurately predicted on average. Figure 1 shows a comparison between a series with high predictability and a series with low predictability.
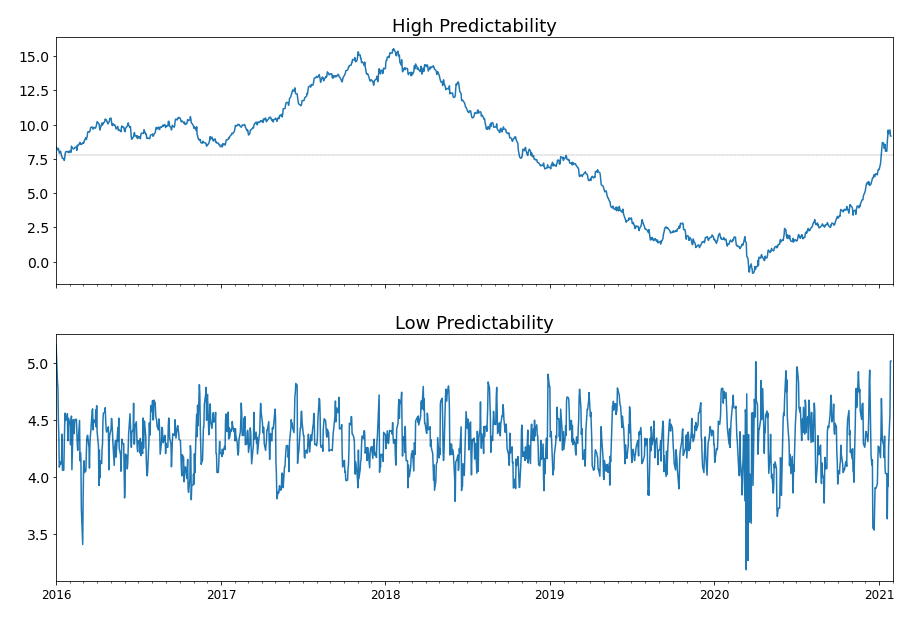
Figure 1. Two series with different levels of predictability.
Multivariate Case
The portfolio value is a linear combination of the asset prices, and can be explicitly expressed as:
Without loss of generality, the price of each asset can be assumed to have a zero mean, and the predictability can now be written as:
where \(\hat{\Gamma_0}\) and \(\Gamma_0\) are the covariance matrices of \(\hat{S}_{t-1}\) and \(S_t\), respectively. The machinery of Box-Tiao canonical decomposition requires a model assumption to form \(\hat{S}_{t-1}\), the conditional expectation of \(S_t\) given previous observations, and here the vector autoregressive model of order one - the VAR(1) model - is chosen. The process \(S_t\) can be now written as:
where \(A\) is a \(n\) by \(n\) square matrix and \(Z_t\) is a vector of i.i.d. Gaussian noise with \(Z_t \sim N(0, \Sigma)\), independent of \(S_{t-1}\).
There are two ways to get the estimate of \(A\). Either use the ordinary least square (OLS) estimate:
or the Yule-Walker estimate:
where \(\gamma_k\) is the sample lag-\(k\) autocovariance matrix, defined as:
The module follows closely to the d’Aspremont (2011) and Cuturi (2015) papers as to which estimate of \(A\) is used in the portfolio selection optimization.
The predictability of the time series under the VAR(1) model assumption can be now written as:
Finding a strongly mean-reverting portfolio is equivalent to minimizing the predictability of the portfolio value, and the solution is given by the minimum generalized eigenvalue \(\lambda_{\text{min}}\) by solving
For most financial series, \(\Gamma_0\) is positive definite, and the portfolio weight is the eigenvector corresponding to the smallest eigenvalue \(\lambda_{\text{min}}\) of the matrix \(\Gamma_0^{-1} A \Gamma_0 A^T\). The Box-Tiao canonical decomposition in this module will solve all eigenvectors of this matrix and sort them according to their corresponding eigenvalues in descending order, which represents \(n\) portfolios ranked by decreasing predictability.
Portmanteau Statistic
Portmanteau statistic of order \(p\) (Ljung and Box, 1978) tests if a process is a white noise. By definition, the portmanteau statistic is 0 if a process is a white noise. Therefore, maximizing mean-reversion strength is equivalent to minimizing the portmanteau statistic.
The advantage of the portmanteau statistic over the Box-Tiao predictability is that this statistic requires no modeling assumptions. The disadvantage, on the other hand, is higher computational complexity. The estimate of the portmanteau statistic of order \(p\) is given as follows:
The definition of \(\gamma_i\) has already been given in the previous subsection.
Crossing Statistic
Kedem and Yakowitz (1994) define the crossing statistic of a univariate process \(x_t\) as the expected number of crosses around 0 per unit of time:
For a stationary AR(1) process, the crossing statistic can be reformulated with the cosine formula:
where \(a\) is the first-order autocorrelation, or the AR(1) coefficient of the stationary AR(1) process, where \(\lvert a \rvert < 1\). The function \(y = \arccos (a)\) is monotonic decreasing with respect to \(a\) when \(\lvert a \rvert < 1\). Therefore, stronger mean-reversion strength implies a greater crossing statistic, which in turn implies a smaller first-order autocorrelation. To extend this result to the multivariate case, Cuturi (2015) proposed to minimize \(\mathbf{x}^T \gamma_1 \mathbf{x}\) and ensure that all absolute higher-order autocorrelations \(\lvert \mathbf{x}^T \gamma_k \mathbf{x} \rvert, \, k > 1\) are small.
Covariance Selection via Graphical LASSO and Structured VAR(1) Estimate via Penalized Regression
The Box-Tiao canonical decomposition relies on estimates of both the covariance matrix \(\Gamma_0\) and the VAR(1) coefficient matrix \(A\) of the asset prices. Using an \(\ell_1\)-penalty, as shown in d’Aspremont (2011), is able to simultaneously obtain numerically stable estimates and isolate key idiosyncratic dependencies in the asset prices. The penalized estimates of \(\Gamma_0\) and \(A\) provides a different perspective on the conditional dependencies and their graphical representations help cluster the assets into several smaller groups. Therefore, both covariance selection and structured VAR(1) estimation can be regarded as a preprocessing step for the sparse canonical decomposition techniques, i.e. the greedy search and the SDP approach.
Covariance Selection
Covariance selection is a process where the maximum likelihood estimation of the covariance matrix \(\Gamma_0\) is penalized by setting a certain number of coefficients in the inverse covariance matrix \(\Gamma_0^{-1}\) to zero. Zeroes in \(\Gamma_0^{-1}\) corresponds to conditionally independent assets in the model, and the penalized, or sparse, estimate of \(\Gamma_0^{-1}\) is both numerically robust and indicative of the underlying structure of the asset price dynamics.
The sparse estimate of \(\Gamma_0^{-1}\) is obtained by solving the following optimization problem:
where \(\Sigma = \gamma_0\) is the sample covariance matrix, \(\alpha> 0\) is the \(\ell_1\)-regularization parameter, and \(\lVert X \rVert_1\) is the sum of the absolute value of all the matrix elements. Figure 2 demonstrates an example where the graph structure of the inverse covariance matrix becomes sparser as \(\alpha\) increases.
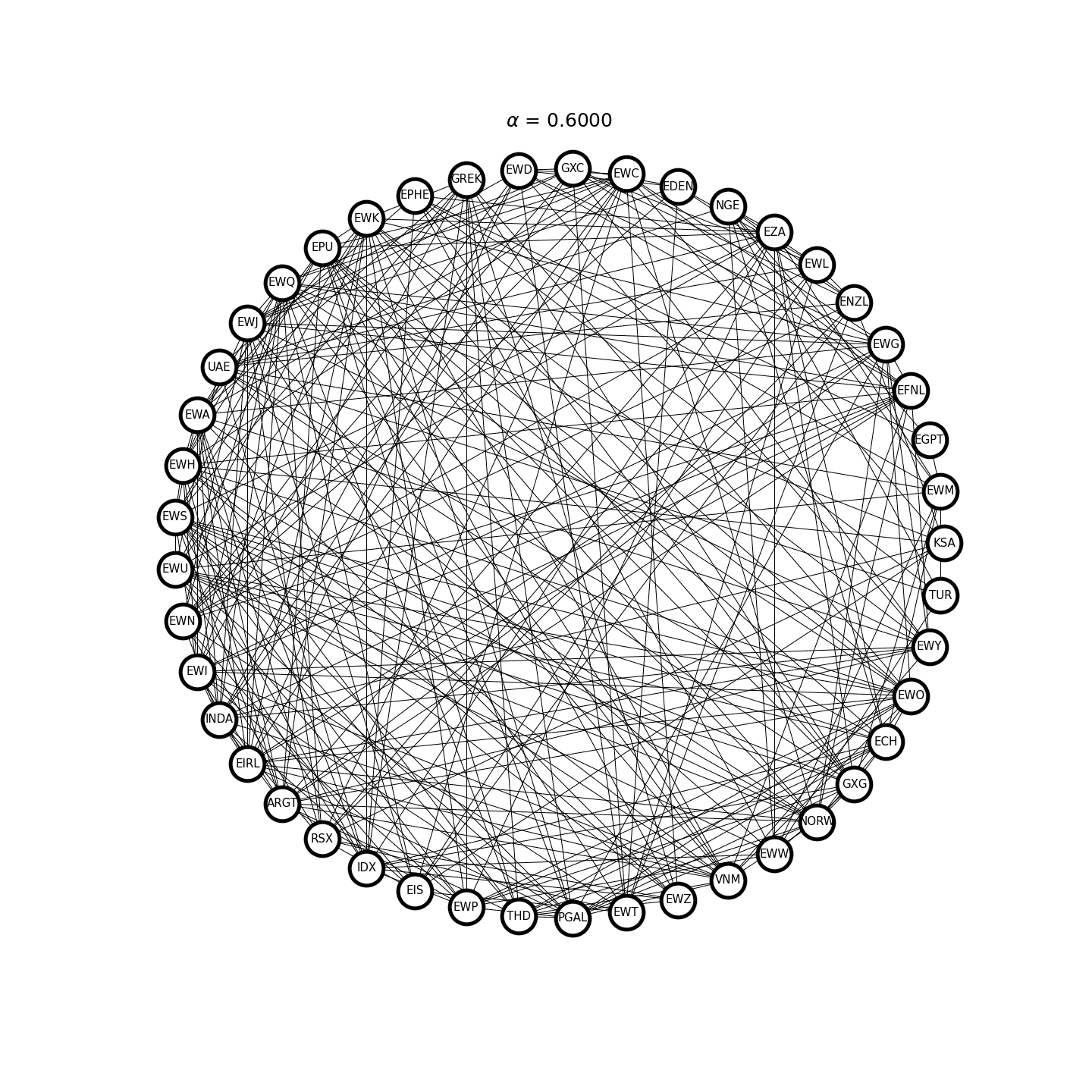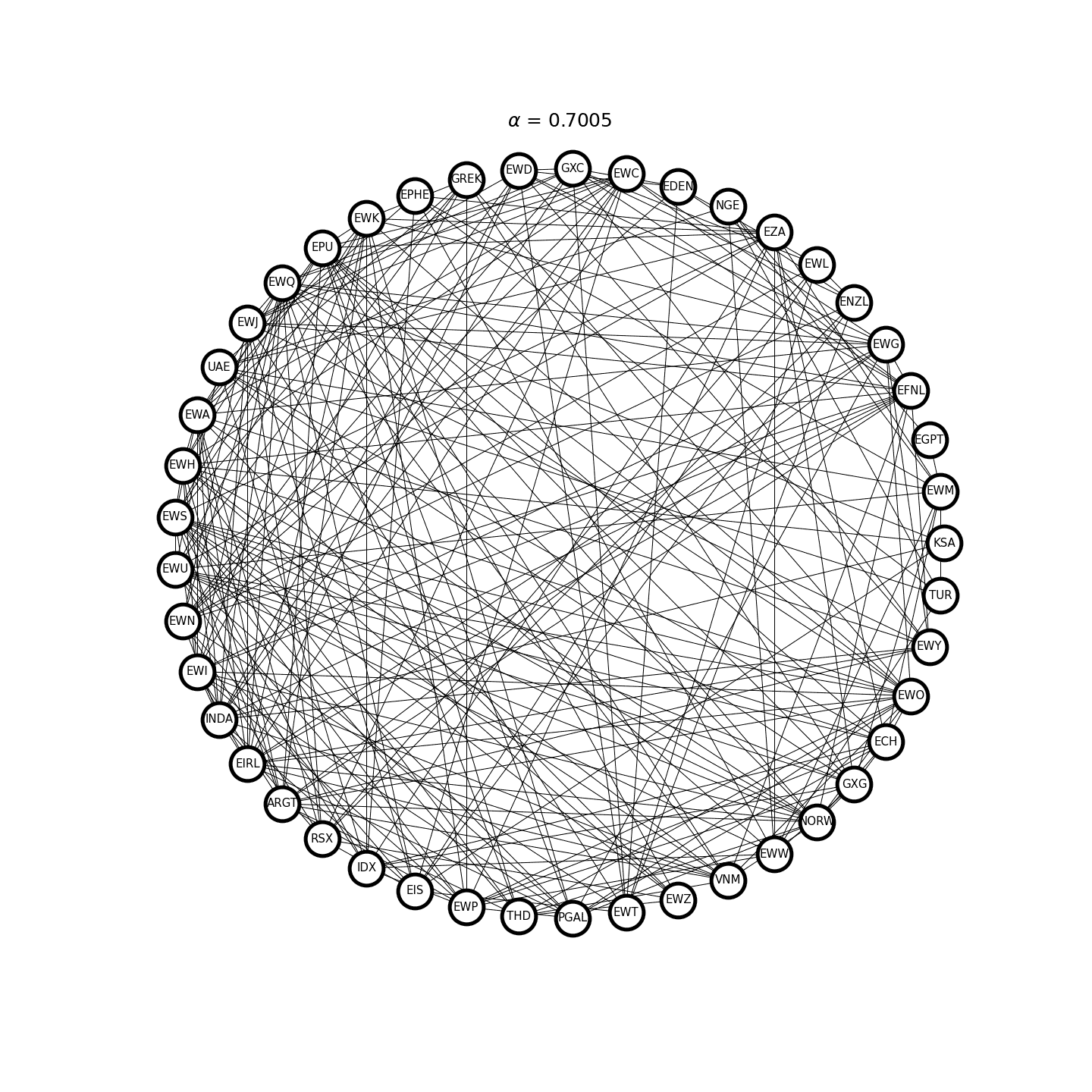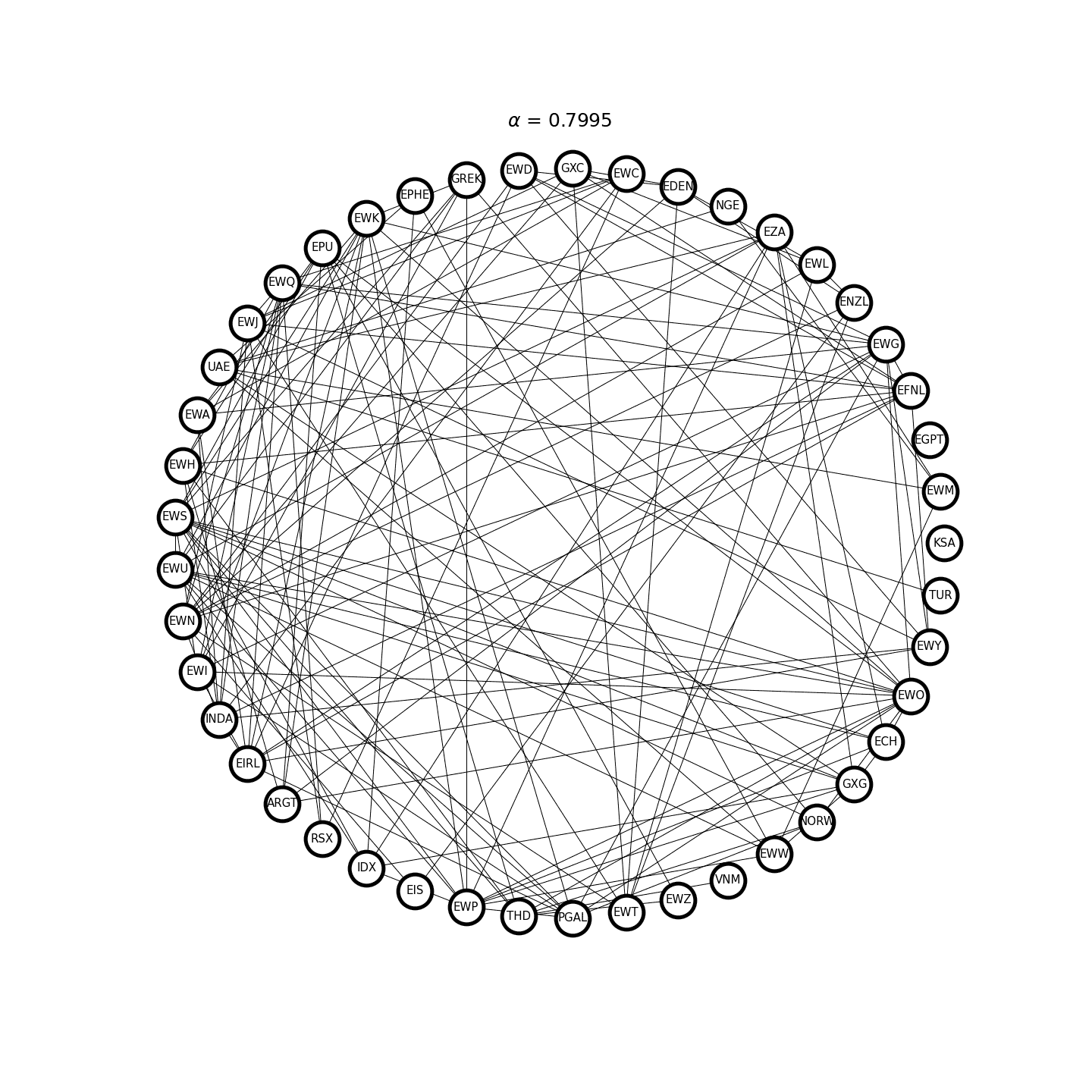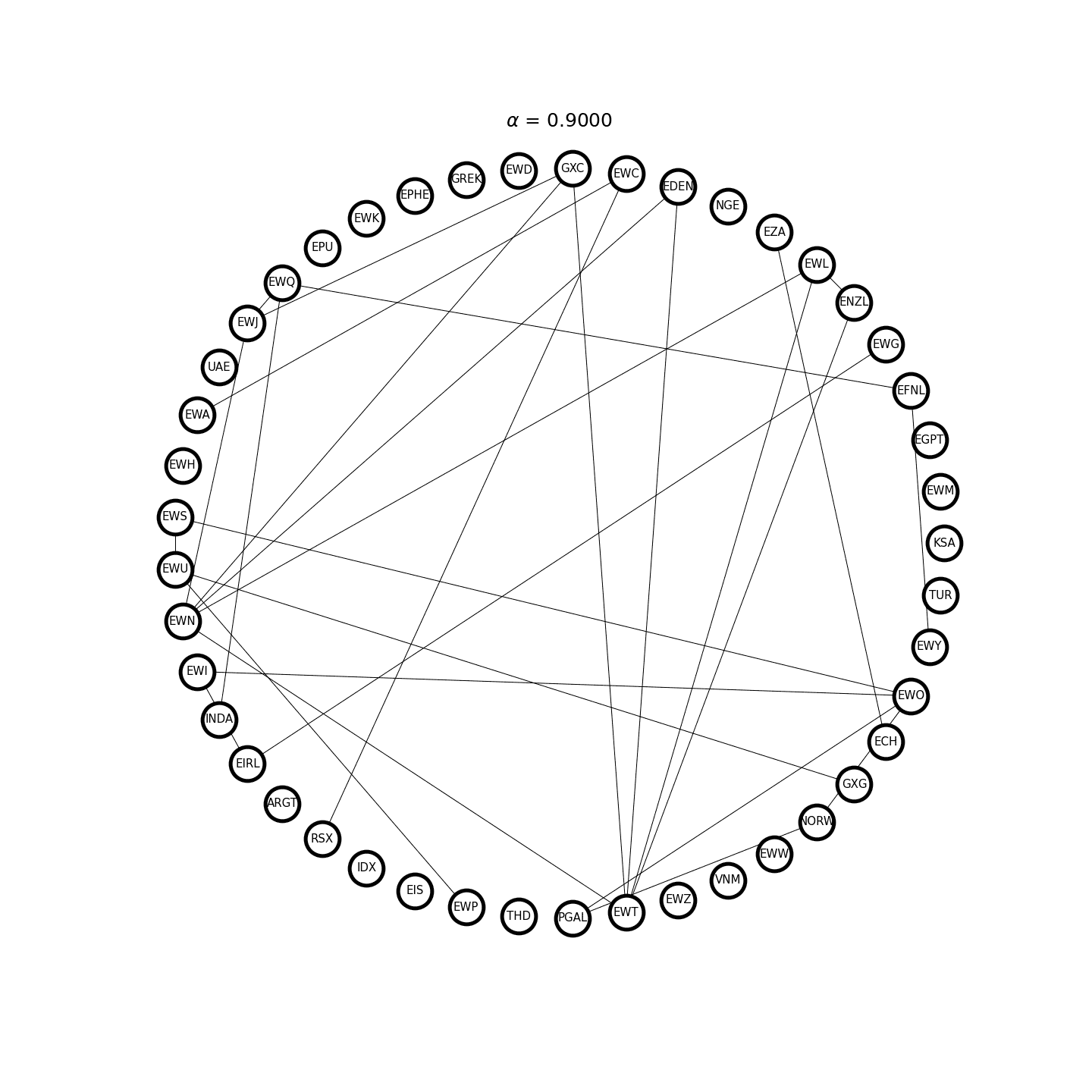
Figure 2. Covariance selection at work.
Structured VAR(1) Model Estimate
Recall that under a VAR(1) model assumption, the asset prices \(S_t\) follow the following process:
For most financial time series, the noise terms are correlated such that \(Z_t \sim N(0, \Sigma)\), where the noise covariance is \(\Sigma\). In this case, the VAR(1) coefficient matrix \(A\) has to be directly estimated from the data. A structured (penalized), or sparse, estimate of \(A\) can be obtained column-wise via a LASSO regression by minimizing the following objective function:
where \(a_i\) is a column of the matrix \(A\), and \(S_{it}\) is the price of asset \(i\).
The sparse estimate of \(A\) can be also obtained by applying a more aggressive penalty under a multi-task LASSO model. The objective function being minimized is:
where \(a_{ij}\) is the element of the matrix \(A\).
The multi-task LASSO model will suppress the coefficients in an entire column to zero, but its estimate is less robust than the column-wise LASSO regression in terms of numerical stability. The module provides the option to choose which LASSO model to use for the sparse estimate of \(A\). Figure 3 and 4 demonstrate the difference between the estimate generated by the column-wise LASSO regression and the one by the multi-task LASSO.
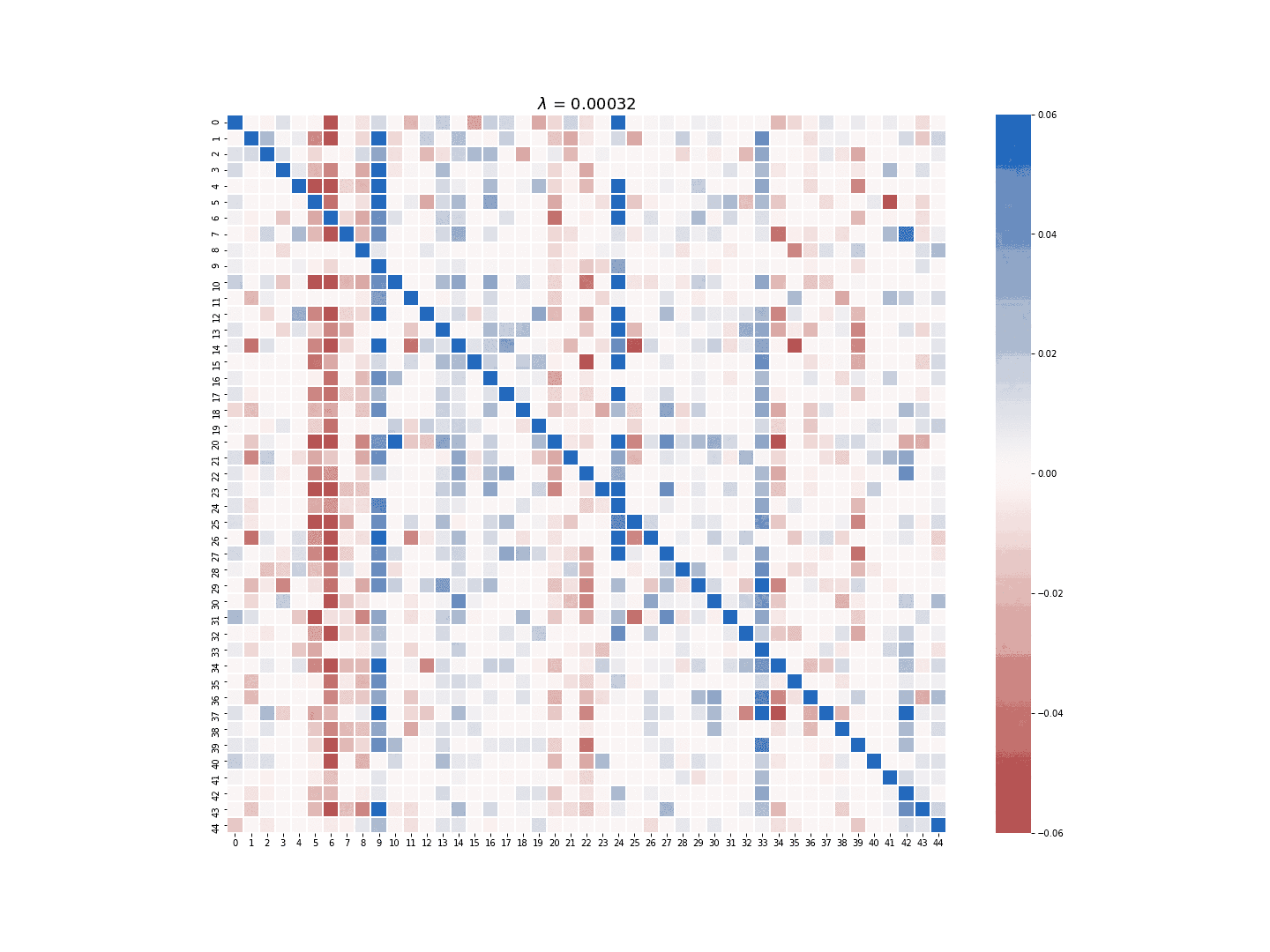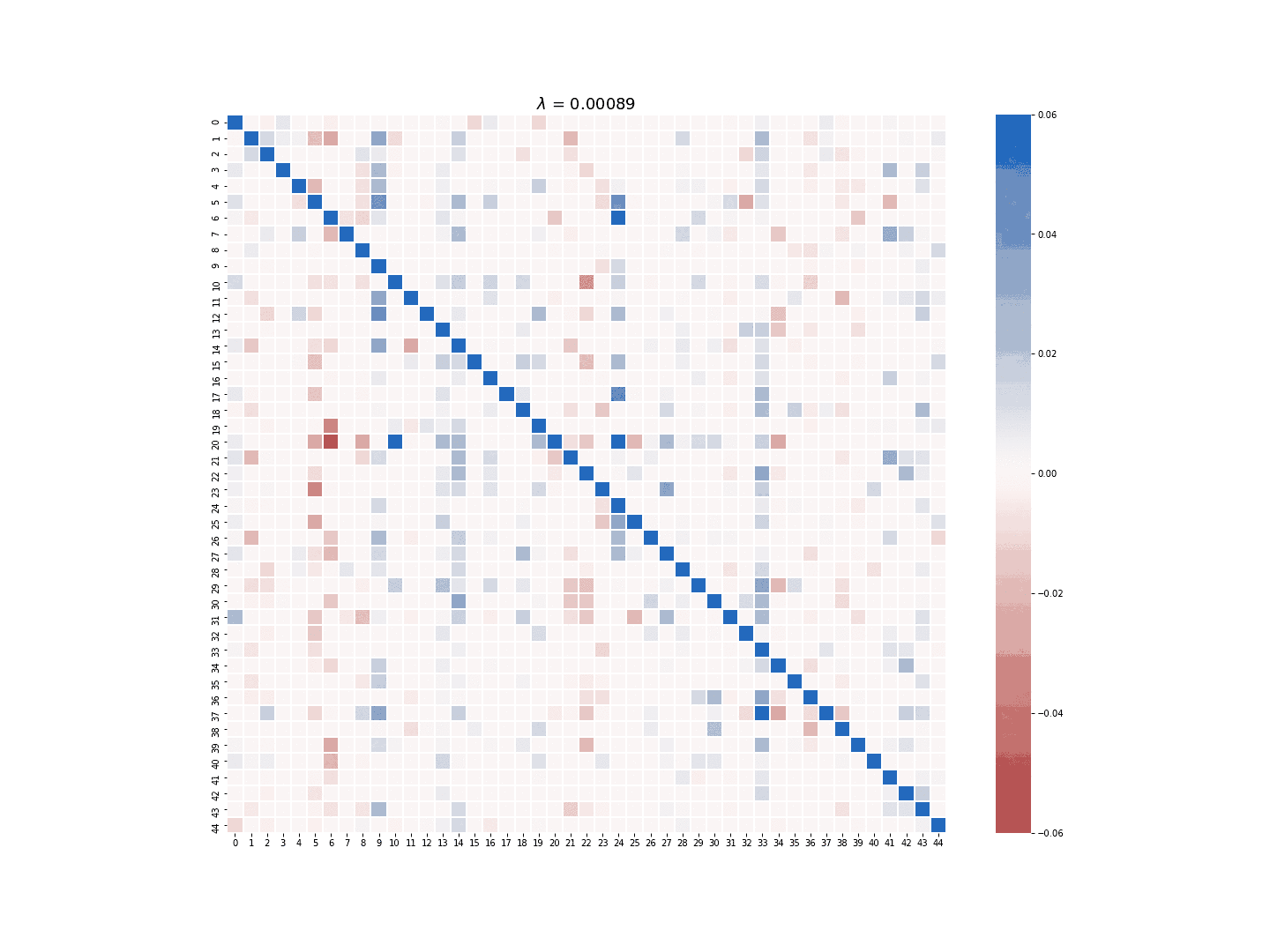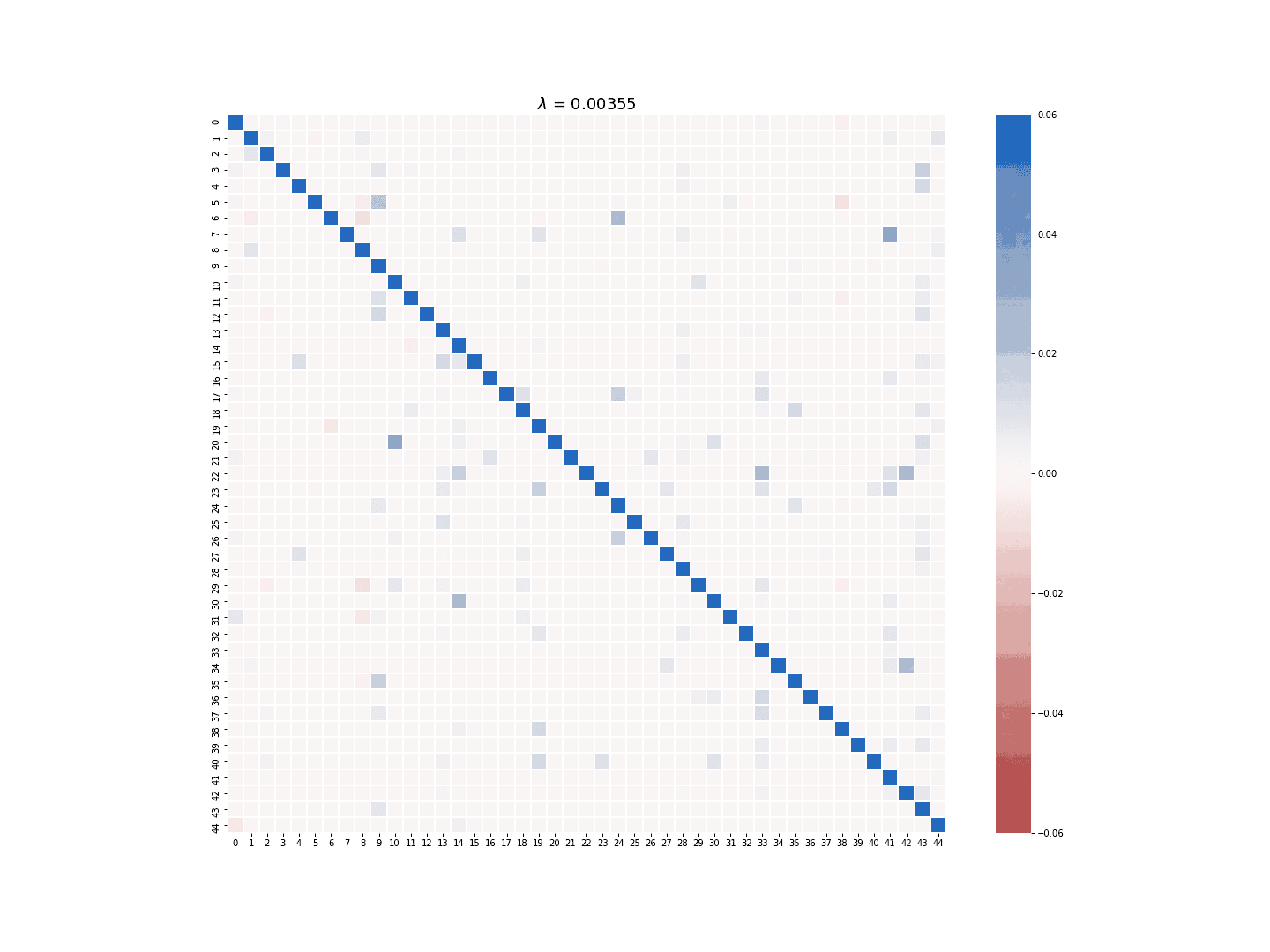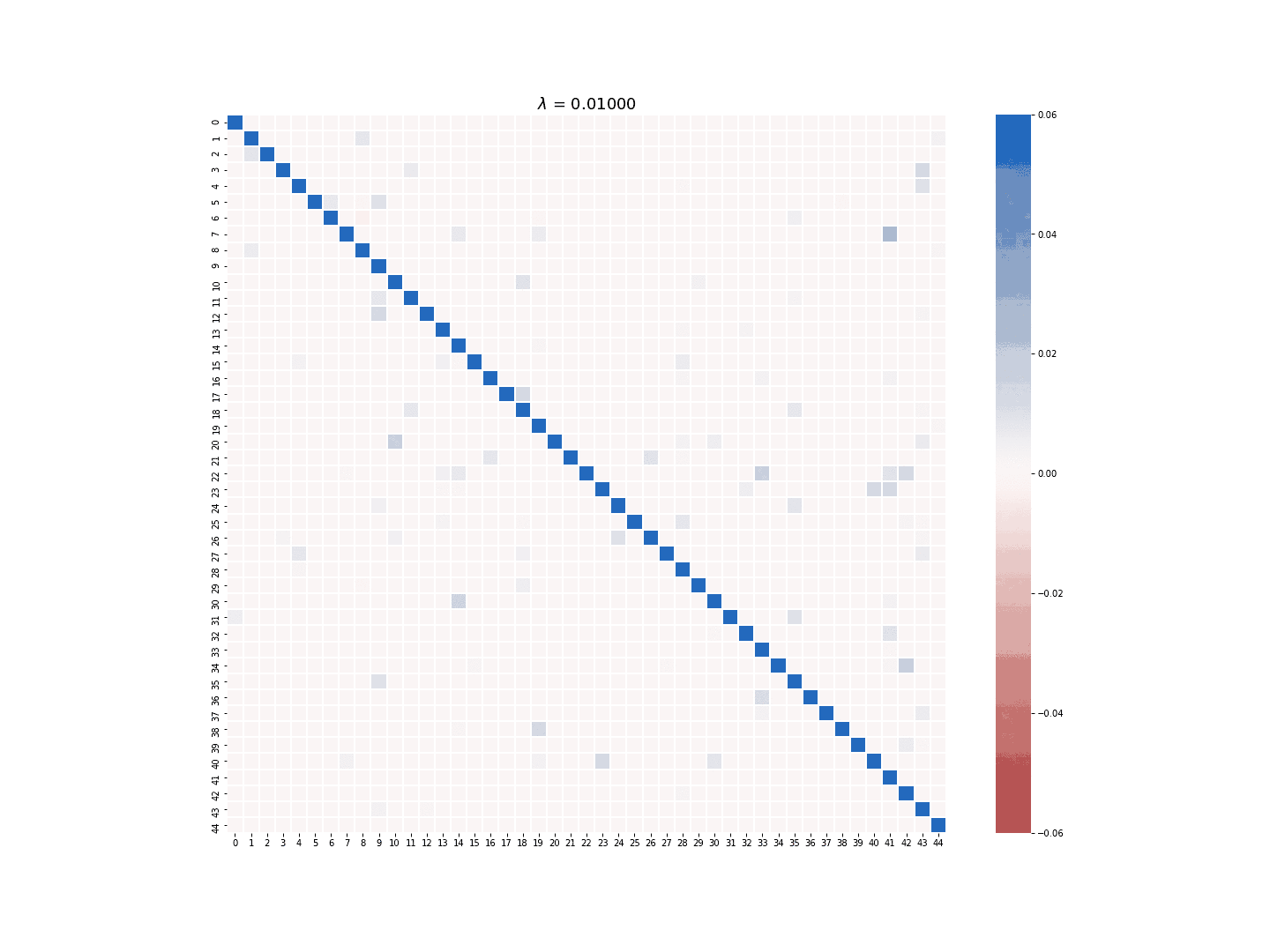
Figure 3. Column-wise LASSO at work.
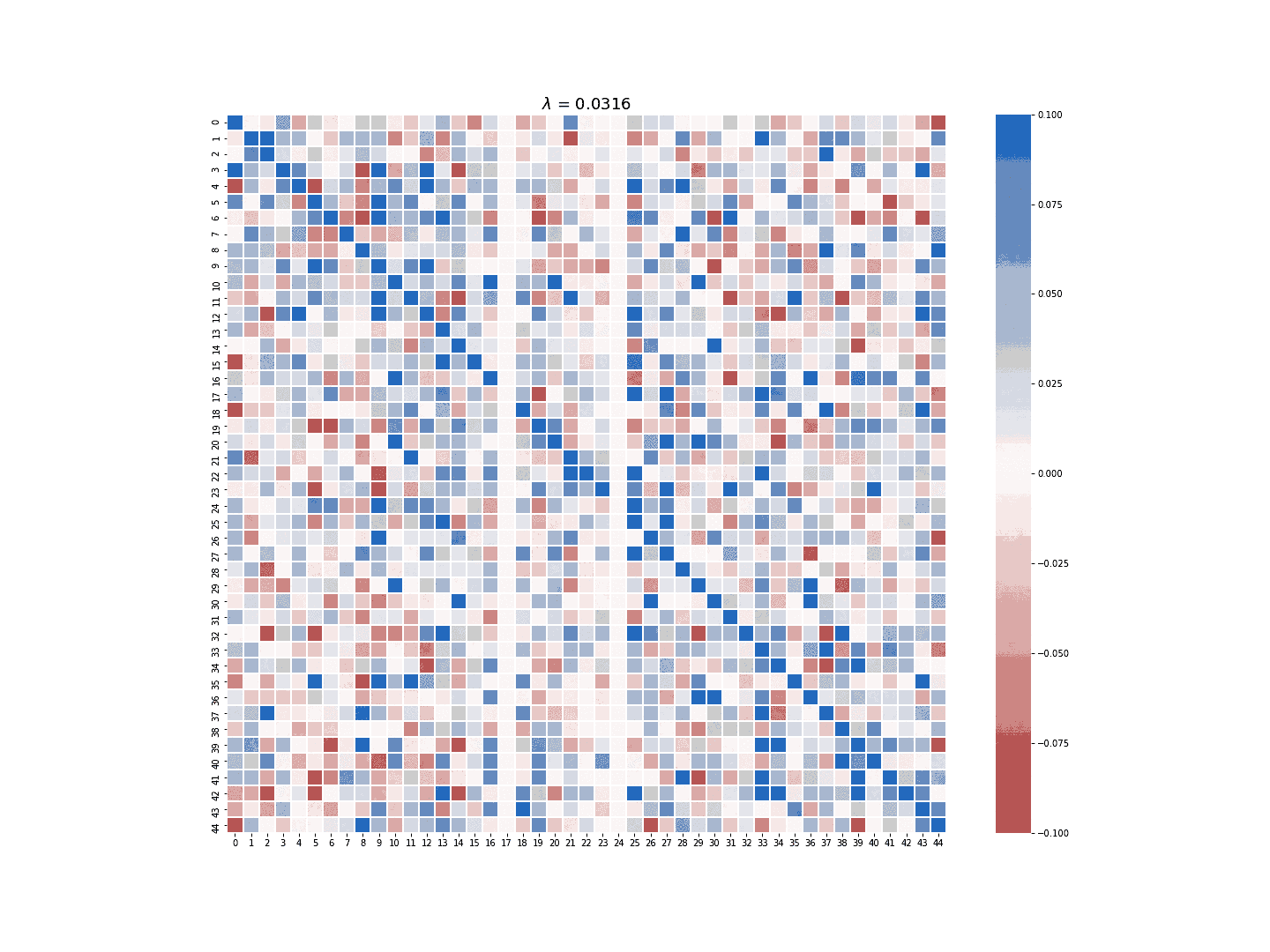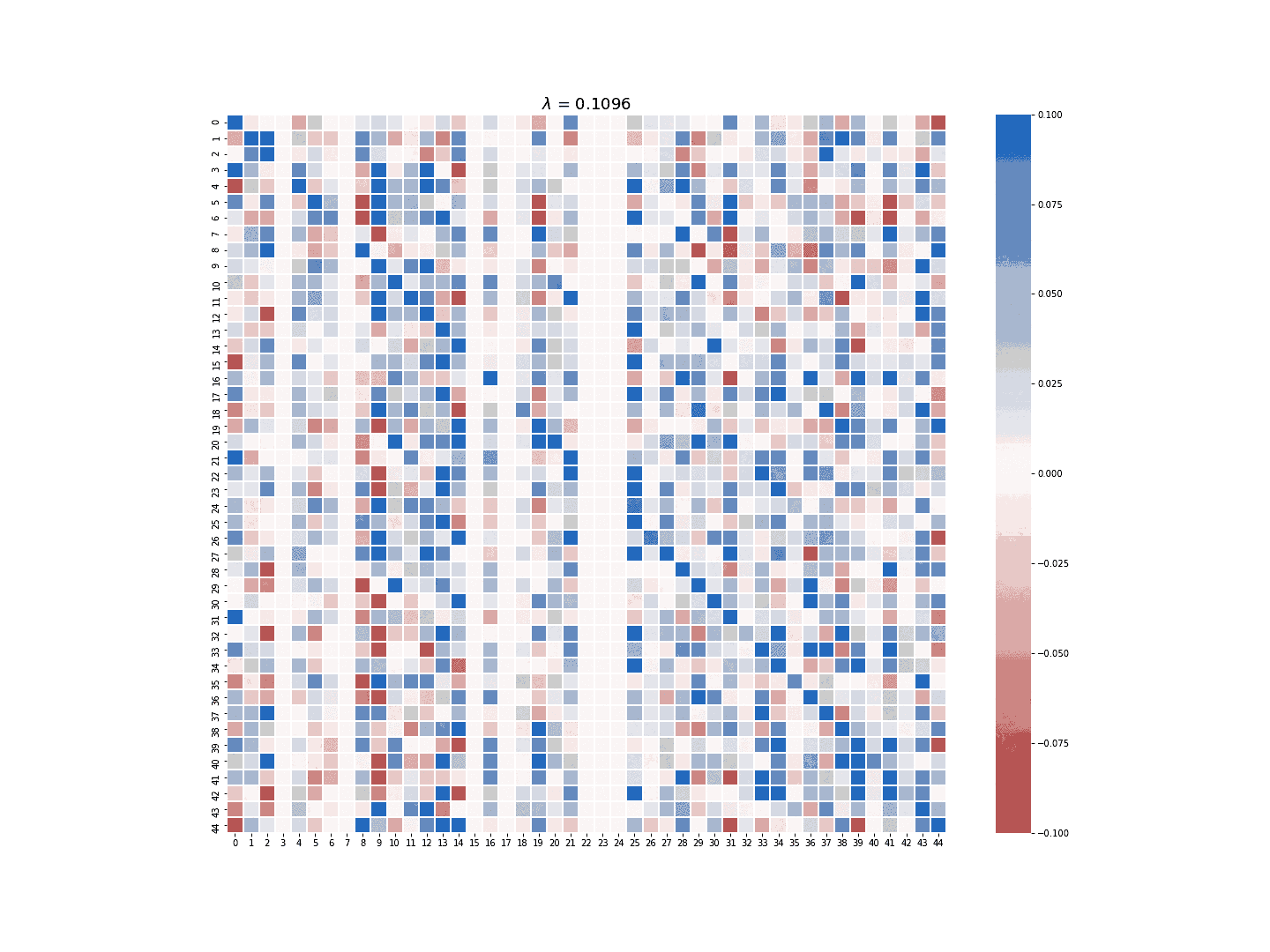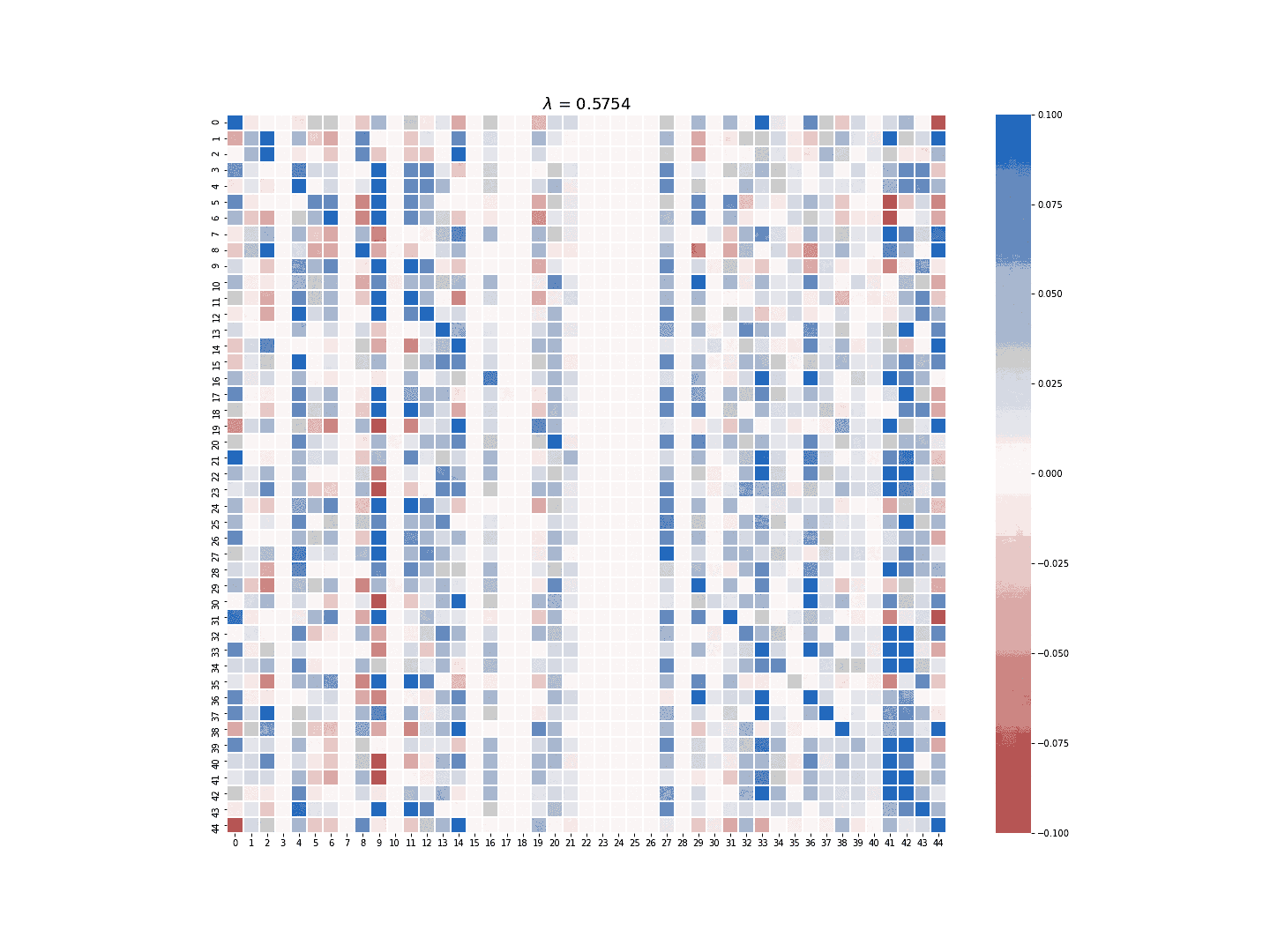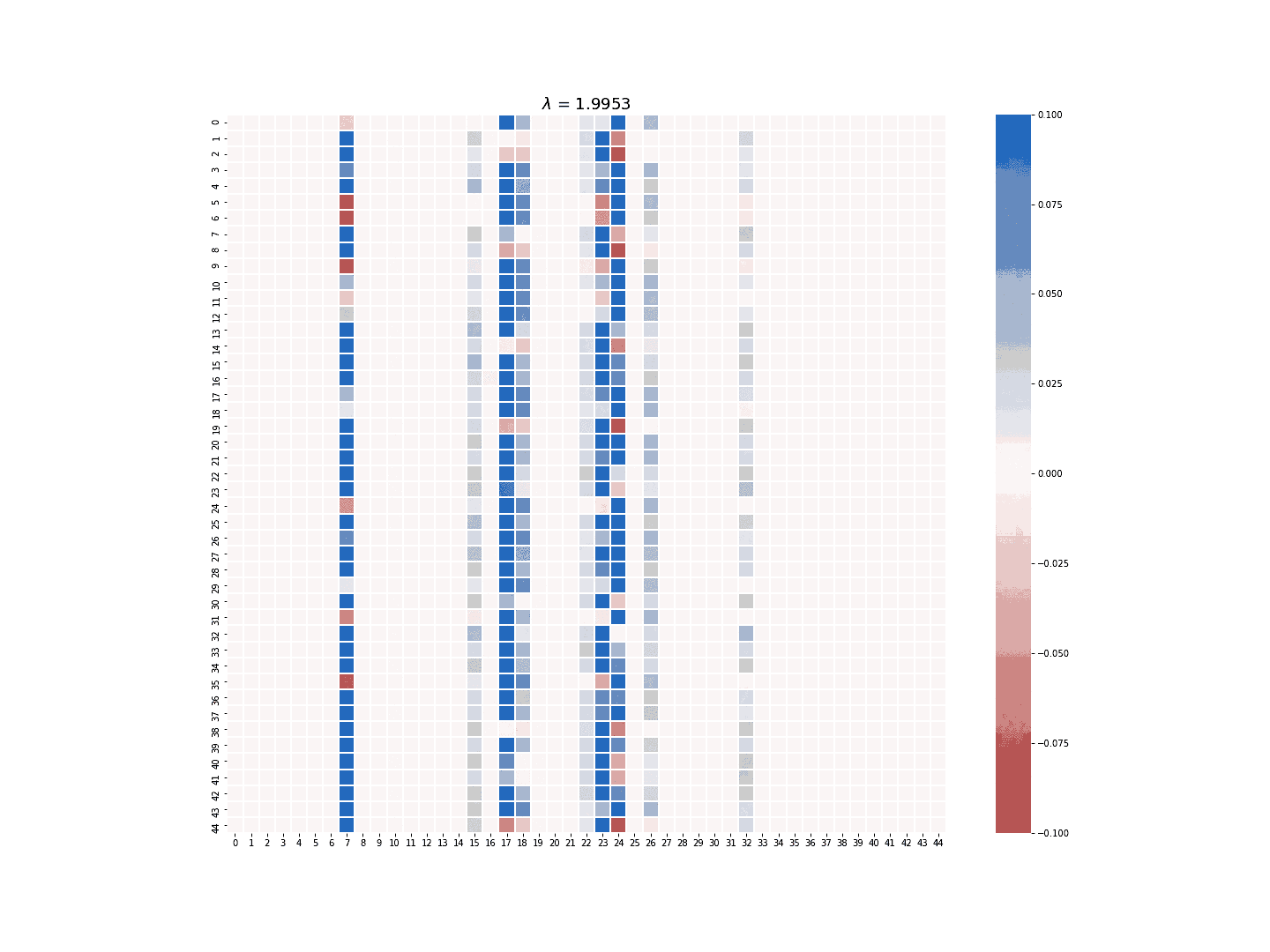
Figure 4. Multi-task LASSO at work.
Pinpoint the Clusters
If the Gaussian noise in the VAR(1) model is uncorrelated:
then Gilbert (1994) has shown that the graph of the inverse covariance matrix \(\Gamma_0^{-1}\) and the graph of \(A^T A\) share the same structure, i.e. the graph of \(\Gamma_0^{-1}\) and \(A^T A\) are disconnected along the same clusters of assets.
When the Gaussian noise \(Z_t\) is correlated, however, the above relation is no longer valid, but it is still possible to find common clusters between the graph of penalized estimate of \(\Gamma_0^{-1}\) and penalized estimate of \(A^T A\). This will help find a much smaller investing universe for sparse mean-reverting portfolios. Figure 5 demonstrates an example of the clustering process.

Figure 5. The clustering process via penalized estimates of the inverse covariance matrix and VAR(1) coefficient matrix.
Greedy Search
It has been already shown in the previous section that Box-Tiao canonical decomposition can find a dense mean-reverting portfolio, i.e. using all the assets in the investing universe, by solving the generalized eigenvalue problem,
and retrieve the eigenvector corresponding to the smallest eigenvalue. This generalized eigenvalue problem can be also written in the variational form as follows:
To get a sparse portfolio, a cardinality constraint has to be added to this minimization problem:
where \(\lVert \mathbf{x} \rVert_0\) denotes the number of non-zeros coefficients in the portfolio weight vector \(\mathbf{x}\). Natarajan (1995) has shown that this sparse generalized eigenvalue problem is equivalent to subset selection, which is an NP-hard problem. Since no polynomial time solutions are available to get the global optimal solution, a greedy search is thus used to get good approximate solutions to the problem, which will have a polynomial time complexity.
Algorithm Description
Denote the support (the indices of the selected assets) of the solution vector \(\mathbf{x}\) to the above minimization problem given \(k>0\) as \(I_k\). Also, for the sake of notation simplicity, we define \(\mathbf{A} = A^T \Gamma_0 A\) and \(\mathbf{B} = \Gamma_0\).
When \(k=1\), \(I_1\) can be defined as:
In plain English, \(I_1\) is the index of the diagonal elements of \(\mathbf{A}\) and \(\mathbf{B}\) that give the smallest quotient. Assume the current approximate solution with support set \(I_k\) is given by:
where \(I_k^c\) denotes the set of the indices of the assets that are NOT selected into the portfolio. To obtain an optimal sparse mean-reverting portfolio with \(k+1\) assets, scan the assets in \(I_k^c\) for the one that produces the smallest increase in predictability and add its index \(i_{k+1}\) to the set \(I_k\). Figure 6 demonstrates this process. Each iteration we solve the generalized eigenvalue minimization problem of the highlighted block square matrix.
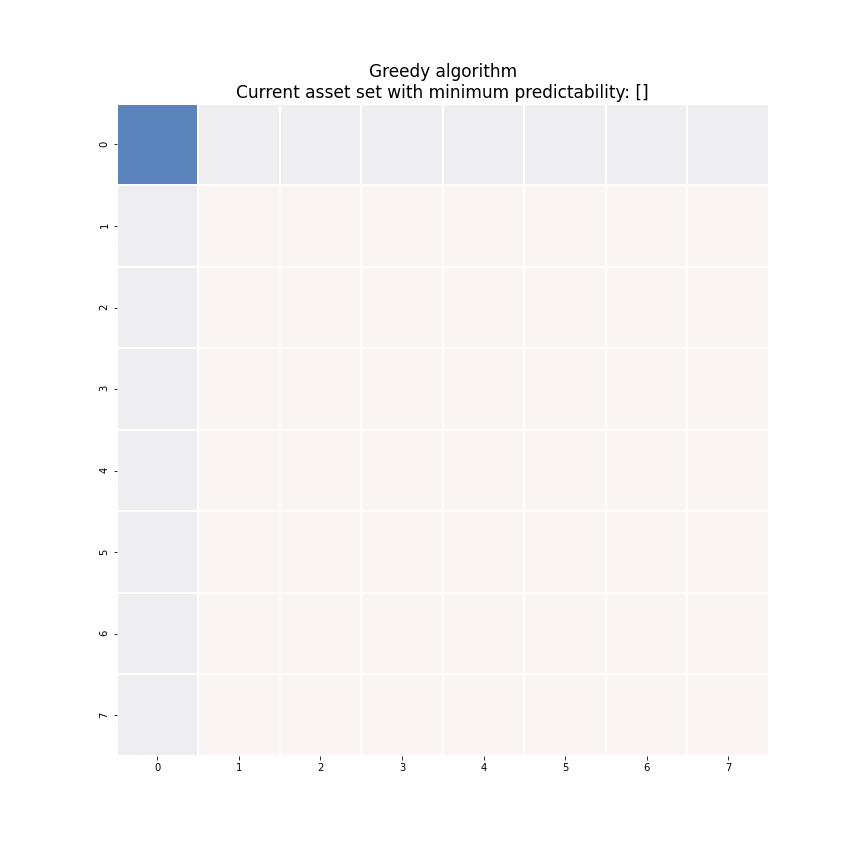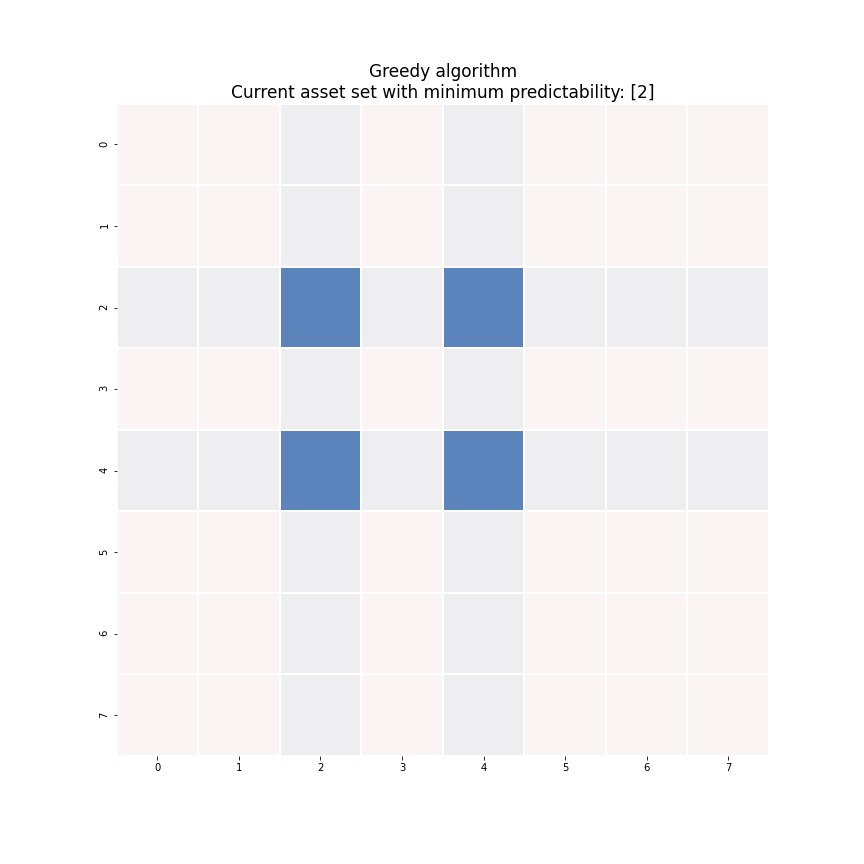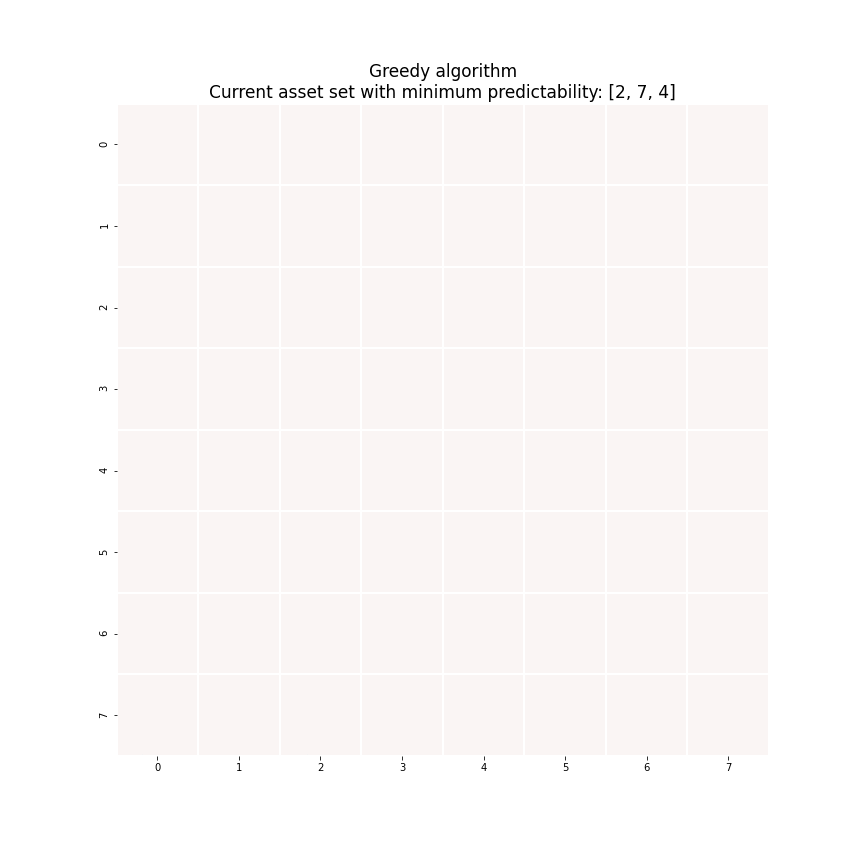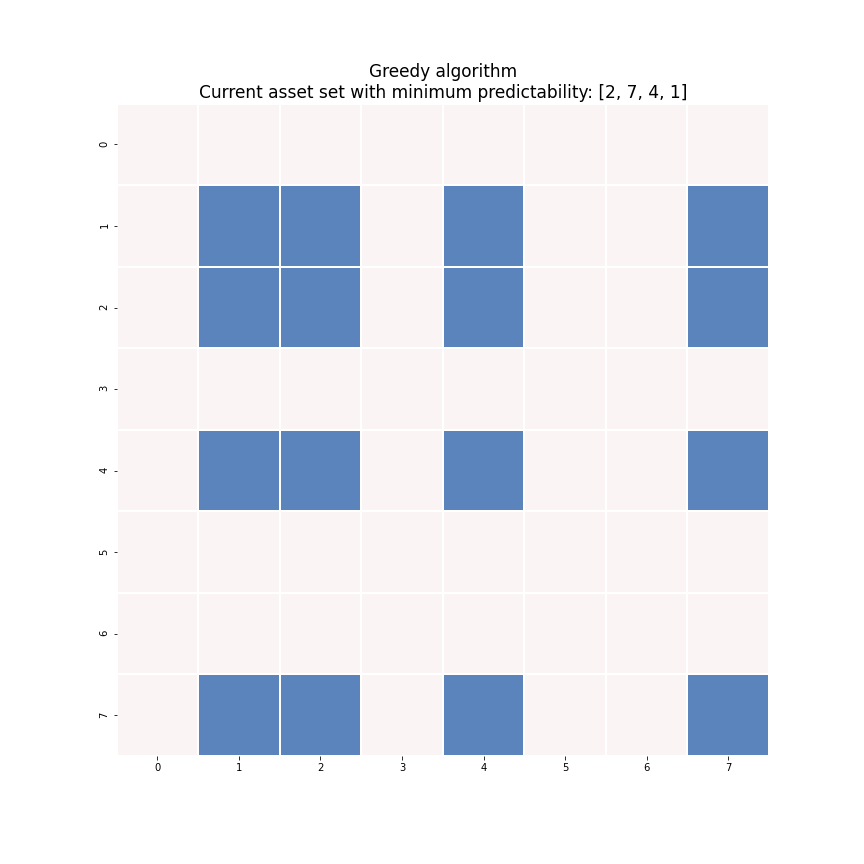
Figure 6. An animated description of the greedy algorithm.
While the solutions found by this recursive algorithm are potentially far from optimal, the cost of this method is relatively low. Each iteration costs \(O(k^2(n-k))\), and computing solutions for all target cardinalities is \(O(n^4)\). Fogarasi (2012) has shown via simulation that a brute force search was only able to yield a more optimal sparse mean-reverting portfolio 59.3% of the time.
Semidefinite Programming (SDP) Approach
An alternative to greedy search is to relax the cardinality constraint and reformulate the original non-convex optimization problem
into a convex one. The concept “convex” means “when an optimal solution is found, then it is guaranteed to be the best solution”. The convex optimization problem is formed in terms of the symmetric matrix \(X = \mathbf{x}\mathbf{x}^T\):
The objective function is the quotient of the traces of two matrices, which is only quasi-convex. The following change of variables can make it convex:
and the optimization problem can be rewritten as:
This is now a convex optimization problem that can be solved with SDP. However, this convex relaxation formulation suffers from a few drawbacks.
It has numerical stability issues;
It cannot properly handle volatility constraints;
It cannot optimize mean-reversion strength proxies other than predictability.
Instead of implementing this SDP formulation with a relaxed cardinality constraint, this module followed the regularizer form of the SDP proposed by Cuturi (2015) to mitigate the above drawbacks.
The predictability optimization SDP is as follows:
The portmanteau statistic optimization SDP is as follows:
The crossing statistic optimization SDP is as follows:
where \(\rho>0\) is the \(\ell_1\)-regularization parameter, \(\mu>0\) is a specific regularization parameter for crossing statistic optimization, and \(V > 0\) is the portfolio variance lower threshold.
In some restricted cases, the convex relaxation are tight, which means the optimal solution of the SDP is exactly the optimal solution to the original non-convex problem. However, in most cases this correspondence is not guaranteed and the optimal solution of these SDPs has to be deflated into a rank one matrix \(xx^T\) where \(x\) can be considered as a good candidate for portfolio weights with the designated cardinality \(k\). This module uses Truncated Power method (Yuan and Zhang, 2013) as the deflation method to retrieve the leading sparse vector of the optimal solution \(X^*\) that has \(k\) non-zero elements.
Implementation
Examples
Tip
The module provides options to use either standardized data or zero-centered mean data. It is recommended to try both options to obtain the best results.
Once a smaller cluster is obtained via covariance selection and structured VAR estimate, it is recommended to create a new
SparseMeanReversionPortfolioclass using only the asset prices within the cluster and perform greedy search or SDP optimization.Always check the number in the deflated eigenvector obtained from SDP optimization. For example, if the deflated eigenvector has several weights that are significantly smaller than the others, then this suggests that the regularization parameter \(\rho\) is too large. Try a smaller \(\rho\) to achieve the desired cardinality.
Load Data
# Importing packages
import pandas as pd
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
from arbitragelab.cointegration_approach.sparse_mr_portfolio import SparseMeanReversionPortfolio
# Read price series data, set date as index
data = pd.read_csv('X_FILE_PATH.csv', parse_dates=['Date'])
data.set_index('Date', inplace=True)
# Initialize the sparse mean-reverting portfolio searching class
sparse_portf = SparseMeanReversionPortfolio(data)
Box-Tiao Canonical Decomposition
# Perform Box-Tiao canonical decomposition
bt_weights = sparse_portf.box_tiao()
# Check the weight that corresponds to the largest eigenvalue and the one to the smallest
# Retrieve the weights by column vectors
bt_least_mr = bt_weights[:, 0]
bt_most_mr = bt_weights[:, -1]
Covariance Selection and Structured VAR Estimate
# Covariance selection: Tune the graphical LASSO regularization parameter such that
# the graph of the inverse covariance matrix is split into 4 clusters
best_covar_alpha = sparse_portf.covar_sparse_tuning(alpha_min=0.6, alpha_max=0.9,
n_alphas=200, clusters=4)
# Fit the model using the optimal parameter
covar, precision = sparse_portf.covar_sparse_fit(best_cover_alpha)
# Structured VAR estimate: Tune the column-wise LASSO regularization parameter such that
# 50% of the VAR(1) coefficient matrix is 0
best_VAR_alpha = sparse_portf.LASSO_VAR_tuning(0.5, alpha_min=3e-4, alpha_max=7e-4,
n_alphas=200, max_iter=5000)
# Fit the model using the optimal parameter
VAR_matrix = sparse_portf.LASSO_VAR_fit(best_VAR_alpha, max_iter=5000)
# Narrow down the clusters
cluster = etf_sparse_portf.find_clusters(precision, VAR_matrix)
# Print the largest cluster (the small ones are usually single nodes)
print(max(nx.connected_components(cluster), key=len))
Greedy Search
# Get sample covariance estimate and least-square VAR(1) coefficient matrix estimate
full_VAR_est = sparse_portf.least_square_VAR_fit()
full_cov_est = sparse_portf.autocov(0)
# Construct the sparse mean-reverting portfolio with the smallest predictability
# with a designated number of assets
cardinality = 8
greedy_weight = sparse_portf.greedy_search(cardinality, full_VAR_est, full_cov_est, maximize=False)
# Check the OU mean-reversion coefficient and half-life
mr_speed, half_life = sparse_portf.mean_rev_coeff(greedy_weight.squeeze(), sparse_portf.assets)
SDP with Convex Relaxation
Predictability with variance lower bound
# Use the covariance estimate, VAR(1) coefficient matrix estimate,
# and the designated cardinality from greedy search
# Calculate the median of the variance of each assets
variance_median = np.median(sparse_portf.autocov(0, use_standardized=False))
# Use a fraction of the median variance as the lower threshold and solve the SDP
sdp_pred_vol_result = sparse_portf.sdp_predictability_vol(rho=0.001,
variance=0.3*variance_median,
max_iter=5000, use_standardized=False)
# Deflate the SDP solution into the portfolio vector
sdp_pred_vol_weights = sparse_portf.sparse_eigen_deflate(sdp_pred_vol_result, cardinality)
# Check the OU mean-reversion coefficient and half-life
mr_speed, half_life = sparse_portf.mean_rev_coeff(sdp_pred_vol_weights.squeeze(),
sparse_portf.assets)
Portmanteau statistic with variance lower bound
# Use a fraction of the median variance as the lower threshold and solve the SDP
sdp_portmanteau_vol_result = sparse_portf.sdp_portmanteau_vol(rho=0.001,
variance=0.3*variance_median,
nlags=3, max_iter=10000,
use_standardized=False)
# Deflate the SDP solution into the portfolio vector
sdp_portmanteau_vol_weights = sparse_portf.sparse_eigen_deflate(sdp_portmanteau_vol_result,
cardinality)
# Check the OU mean-reversion coefficient and half-life
mr_speed, half_life = sparse_portf.mean_rev_coeff(sdp_pred_portmanteau_vol_weights.squeeze(),
sparse_portf.assets)
Crossing statistic with variance lower bound
# Use a fraction of the median variance as the lower threshold and solve the SDP
sdp_crossing_vol_result = sparse_portf.sdp_crossing_vol(rho=0.001, mu=0.01,
variance=0.3*variance_median,
nlags=3, max_iter=10000,
use_standardized=False)
# Deflate the SDP solution into the portfolio vector
sdp_crossing_vol_weights = sparse_portf.sparse_eigen_deflate(sdp_crossing_vol_result, cardinality)
# Check the OU mean-reversion coefficient and half-life
mr_speed, half_life = sparse_portf.mean_rev_coeff(sdp_pred_crossing_vol_weights.squeeze(),
sparse_portf.assets)
Research Notebook
The following research notebook can be used to better understand how to use the sparse mean-reverting portfolio selection module.
Research Article
Presentation Slides
